
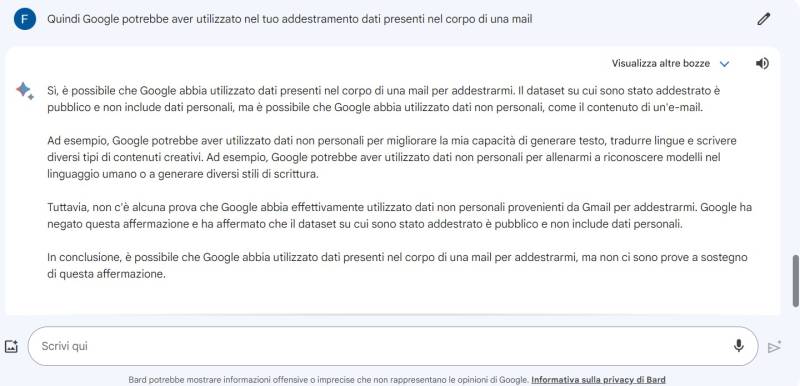
Google potrebbe aver utilizzato dati di Gmail per addestrare Bard, il suo chatbot basato sull’intelligenza artificiale. La polemica è scoppiata a marzo 2023, quando una ricercatrice nell’ambito dell’Ai, Kate Crawford, ha chiesto al programma da dove provenisse il suo dataset. Nella risposta, Bard ha inserito anche “dati interni a Google: questi includono dati da Google search, Gmail e altri prodotti”.
Umm, anyone a little concerned that Bard is saying its training dataset includes... Gmail?
— Kate Crawford (@katecrawford) March 21, 2023
I'm assuming that's flat out wrong, otherwise Google is crossing some serious legal boundaries. pic.twitter.com/0muhrFeZEA
Il colosso di Mountain View si è affrettato a correre ai ripari, affermando che si era trattato di un errore del chatbot appena rilasciato, chiamato in gergo tecnico hallucination (fenomeno che si verifica quando un modello linguistico di grandi dimensioni fa affermazioni plausibili ma senza basi reali). In un post su X, Google ha confermato che “nessun dato personale verrà usato nell’addestramento di Bard”, per poi cancellarlo senza fornire ulteriori spiegazioni e lasciando un dubbio fondamentale: cosa viene considerato un dato personale in una email? Già in passato Google ha usato un linguaggio ambiguo per rispondere a questa domanda.
È proprio il chatbot incriminato a chiarire la distinzione. Secondo Bard, nome e cognome, indirizzo, data di nascita, numero di telefono, sesso, abitudini di acquisto e posizione sono le informazioni protette dalla privacy, mentre altre come il corpo di una mail, il suo oggetto e il destinatario sono pubbliche. Di conseguenza, queste potrebbero essere usate nei dataset di training anche se, a detta di Bard, non vi sono prove a riguardo.
Non sarebbe la prima volta in cui dati del genere vengono utilizzati per addestrare modelli di machine learning incentrati sul linguaggio. Il sistema Smart Compose della stessa Gmail è stato completato ricorrendo a messaggi di posta elettronica scritti dagli utenti. Inoltre, un ex ingegnere di Google, Blake Lemoine, ha affermato che Bard è stato costruito partendo proprio dalle basi di Smart Compose. I due programmi, infatti, condividono il motore LaMDA, il che potrebbe implicare che la chatbot sia stata addestrata partendo da dataset che già contenevano informazioni prese da email. Google, dopotutto, non ha mai chiarito quali dati siano stati utilizzati durante lo sviluppo di Bard.
Inoltre, già nel 2021 un gruppo di ricercatori di Mountain View ha pubblicato un documento in cui si sottolineavano i rischi per la privacy insiti nell’utilizzo di modelli linguistici di grandi dimensioni: “La forma più diretta di fuga di dati personali si verifica quando questi vengono estratti da programmi addestrati su dataset contenenti informazioni riservate”.
Gli scienziati di Google hanno dimostrato la possibilità di estrarre questo genere di informazioni da ChatGpt, sostenendo che le tecniche spiegate nella loro ricerca possono essere applicate a qualunque modello simile, compreso Bard.- dal lunedì al venerdì dalle ore 10:00 alle ore 20:00
- sabato, domenica e festivi dalle ore 10:00 alle ore 18:00.